Building Tree Census: a Django and Next.js platform from local dev to production on GCP
A behind-the-scenes look at Tree Census, a municipal field-operations platform spanning Django/PostGIS, a Next.js dashboard, a Jetpack Compose Android app, and a hardened Google Cloud deployment with IAP-only SSH and Workload Identity Federation in CI.
On this page
Tree Census is a delivery platform for municipal tree-census projects. It was built for Tathastu GIS and Mapping Services, with the first deployment going live for Surendranagar Municipal Corporation. The work spans a Django REST backend with PostGIS, a Next.js operations dashboard, a Kotlin Android survey app, and a single-VM production stack on Google Cloud.
The interesting part of this project was never one isolated feature. It was the amount of coordination required between field collection, geospatial review, operational reporting, authentication, CI, and cloud operations. A surveyor on an Android phone, a supervisor reviewing records on a map, and an administrator watching the production dashboard all needed to trust the same system, and I owned the path from local Docker to a hardened live VM.
The shape of the stack
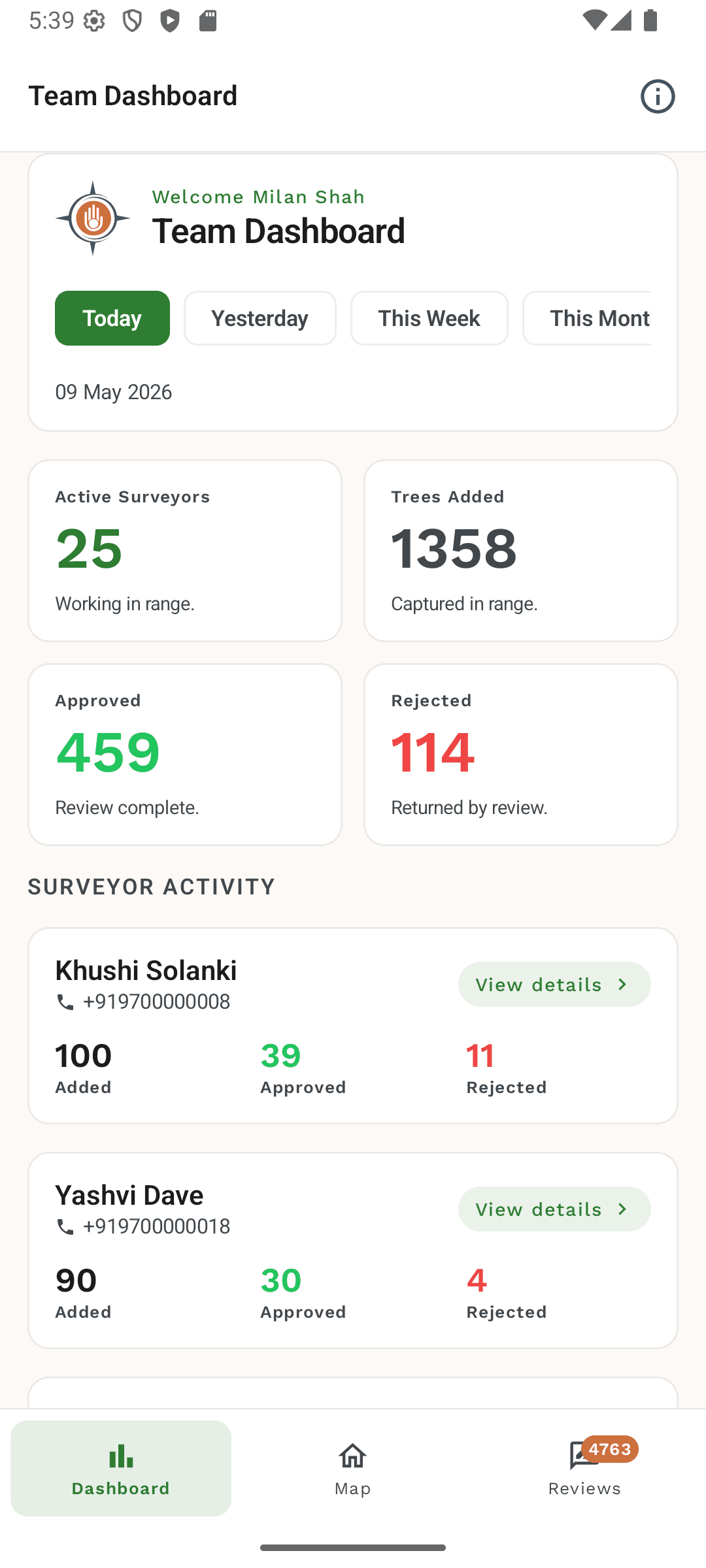
Three surfaces, one production target: a Django REST framework backend with PostGIS, Celery, Redis, and S3-compatible photo storage (MinIO locally, GCS in production); a Next.js dashboard for review, reporting, exports, billing, and user management; and a Kotlin Jetpack Compose Android app with Google Maps, CameraX, Room, and WorkManager for field surveyors.
The web and backend share a single VM in production. The Android client talks to the same backend over HTTPS with certificate pinning.
A Next.js dashboard built for operations
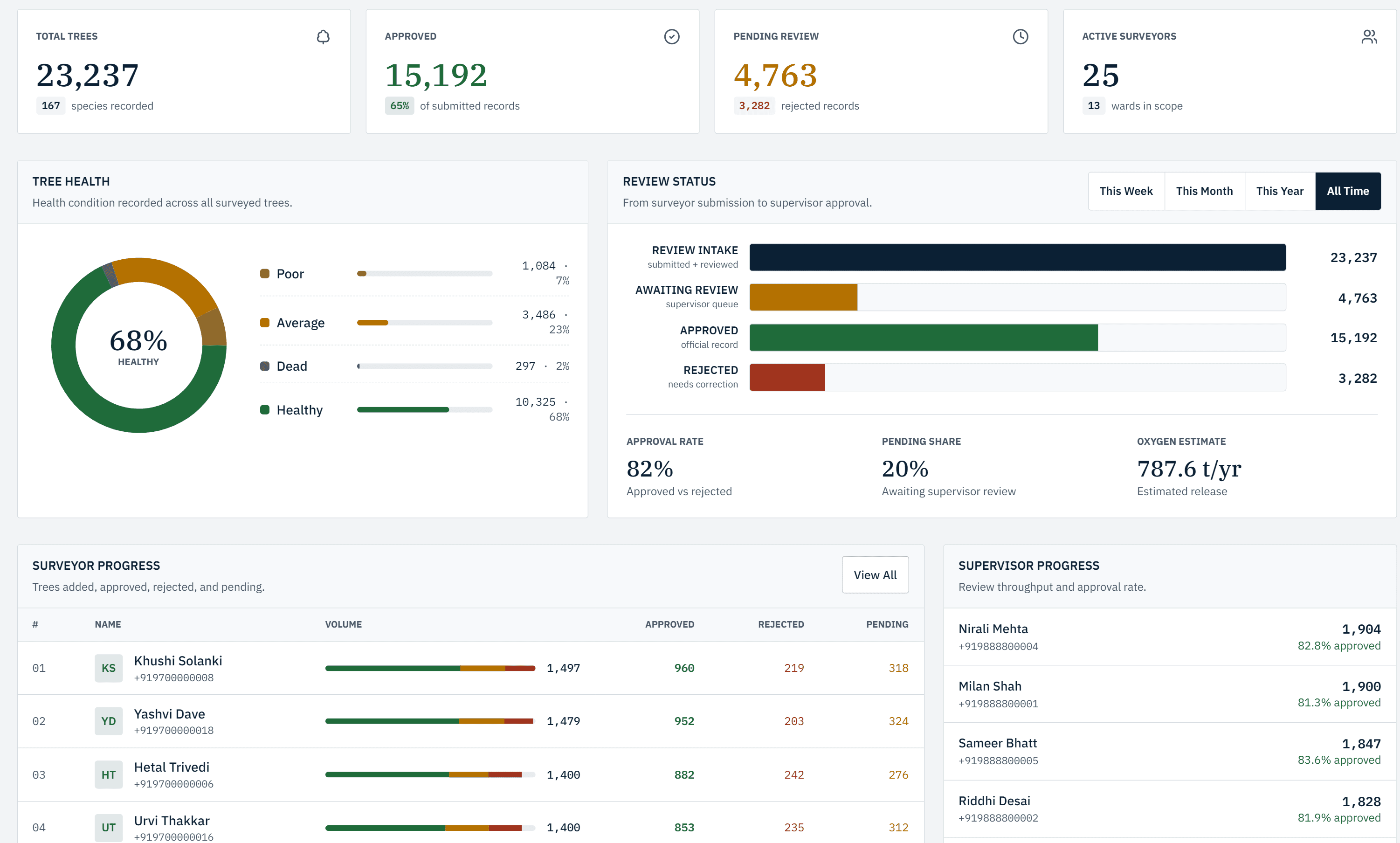
The dashboard is not a vanity chart surface. Supervisors and admins use it to run the census day to day, so the design favors density, URL-synced filters, and explicit states over decorative motion.
The work I am most proud of on the web side: server-action mutations with typed contracts and a small ActionResult discriminated union, so editor flows, role checks, and Supabase wiring all go through a single authorized boundary; a role-gated API proxy that enforces admin-only routes server-side instead of trusting client guards; URL-synced filters for ward, surveyor, species, status, condition, and date range so a supervisor can paste a filtered link and land on the exact same map and table; multi-format exports (PDF, Excel, CSV, GeoJSON, KML) including a filtered tree-export history; and dense data tables that still respect overflow on long census IDs, ward progress that orders numerically instead of lexically, and day-range presets that survive timezone edges.
Hardening the web surface
The dashboard is locked down by default, not as an afterthought. Authentication is Google Sign-In only — no phone OTP, no debug login on production. The backend verifies Google ID tokens; the dashboard receives auth via httpOnly cookies set on the same /api/auth/google-signin/ boundary used by the Android client.
Production sets HSTS with a one-year max-age, a CSP, X-Frame-Options DENY, X-Content-Type-Options nosniff, a strict referrer policy, and a permissions policy. Public schema and docs return 403, secure cookies and SSL redirect are on, and a smoke check is part of every cutover. Pillow and other runtime dependencies are patched as part of the cutover, not deferred to “later”.
Shipping it on Google Cloud
The production stack is intentionally boring: one Compute Engine VM with Nginx terminating TLS, Gunicorn running Django on a Unix socket, Next.js serving the dashboard, Redis backing Celery, and Cloud SQL holding PostgreSQL with PostGIS. Photos live in a Google Cloud Storage bucket. Everything is wired together with systemd units (treecensus-backend, treecensus-celery, treecensus-web, nginx).
Concrete hardening: no public SSH — port 22 is closed and operator access goes through Identity-Aware Proxy with a dedicated VM tag and a single IAP-allowed firewall rule; Cloud SQL is not public — authorized networks are scoped to the VM's static IP, with daily automated backups, point-in-time recovery, and 7-day transaction log retention enabled; the GCS photo bucket has public_access_prevention enforced and soft delete on with a 7-day retention; TLS auto-renew is wired into Nginx as both authenticator and installer with certbot.timer and a 30-day renew margin; ALLOWED_HOSTS is the production domain only; and the first user provisioned in production is the client's superadmin so go-live cannot accidentally ship a half-stale dev account list.
CI and deploy that don't ship long-lived secrets
The repo runs two GitHub Actions workflows. CI on every push runs backend pytest against disposable PostGIS, Redis, and MinIO services started inside the workflow; the web app runs lint and a real production next build; the Android app runs assembleDebug and unit tests. Nothing in CI talks to the live VM, and no production secrets are exposed to PR builds.
Deploys are a separate manual workflow. It uses Workload Identity Federation to authenticate to GCP — the repo holds only GCP_WORKLOAD_IDENTITY_PROVIDER and GCP_SERVICE_ACCOUNT as GitHub secrets, so there is no long-lived JSON service-account key in CI. The job tunnels through IAP, switches to the treecensus service user on the VM, fast-forwards main, rebuilds the web bundle with the production env, restarts the systemd services, and reloads nginx. Production resets, photo-bucket clears, and auth flag flips are deliberately out of scope for the deploy workflow. Those live in a cutover runbook with explicit blast-radius confirmation.
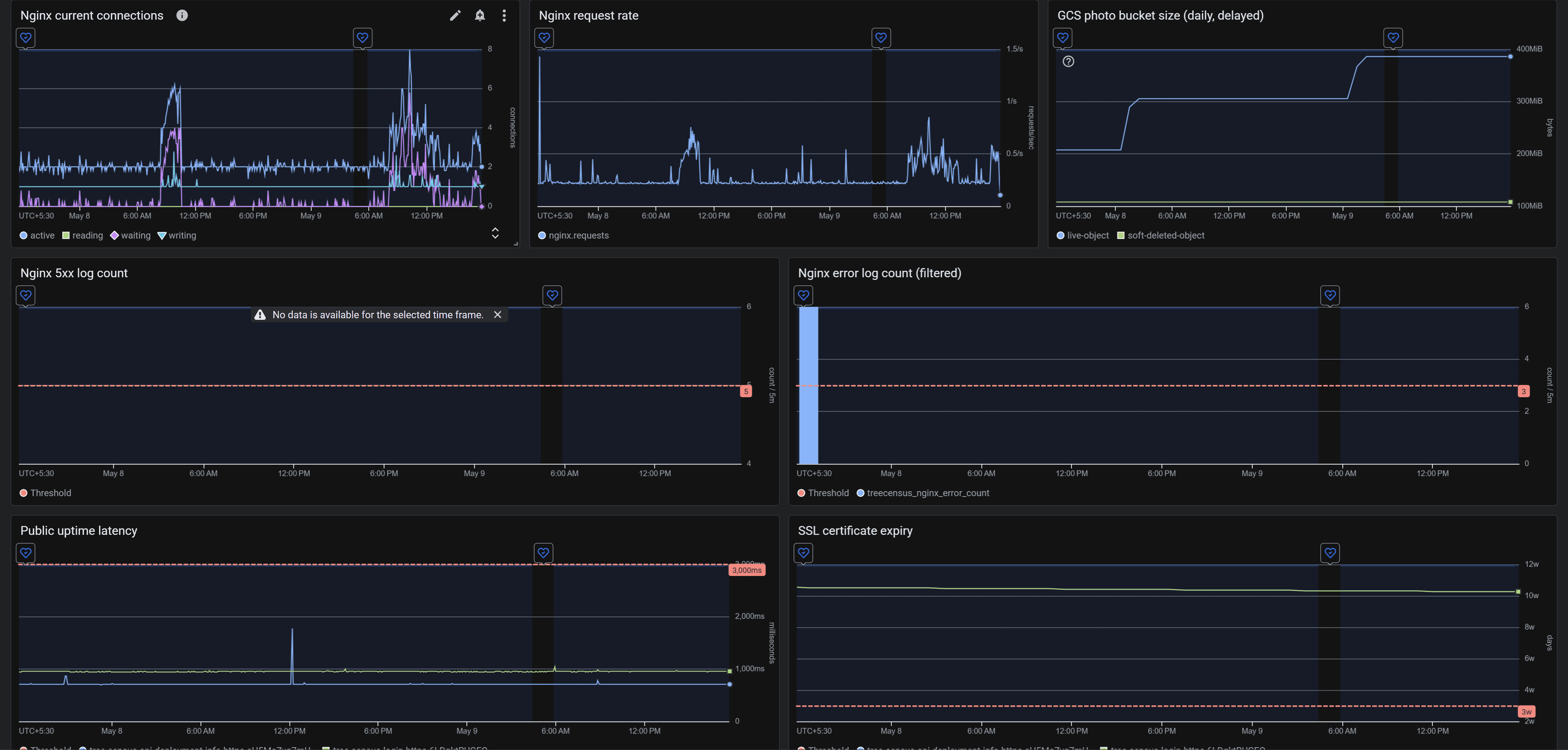
Observability without overbuilding
For the first production baseline, the goal was visibility, not a platform team's worth of dashboards. The setup covers public uptime checks for /login and a deployment-info endpoint; SSL-time-until-expiry; VM CPU, memory, and root disk pressure; Cloud SQL availability, CPU, memory, and storage; Nginx through the Cloud Ops Agent with a stub-status receiver and access/error log collection, plus log-based metrics for 5xx counts and recent error log lines; and GCS storage size and object count for the photo bucket.
Alert policies are configured but intentionally in-console only for the first rollout window. Notification channels are easy to add once the noise floor is calibrated. That setup is enough to triage a real incident, and it leaves room for a richer telemetry layer once we have real production traffic shapes to design for.
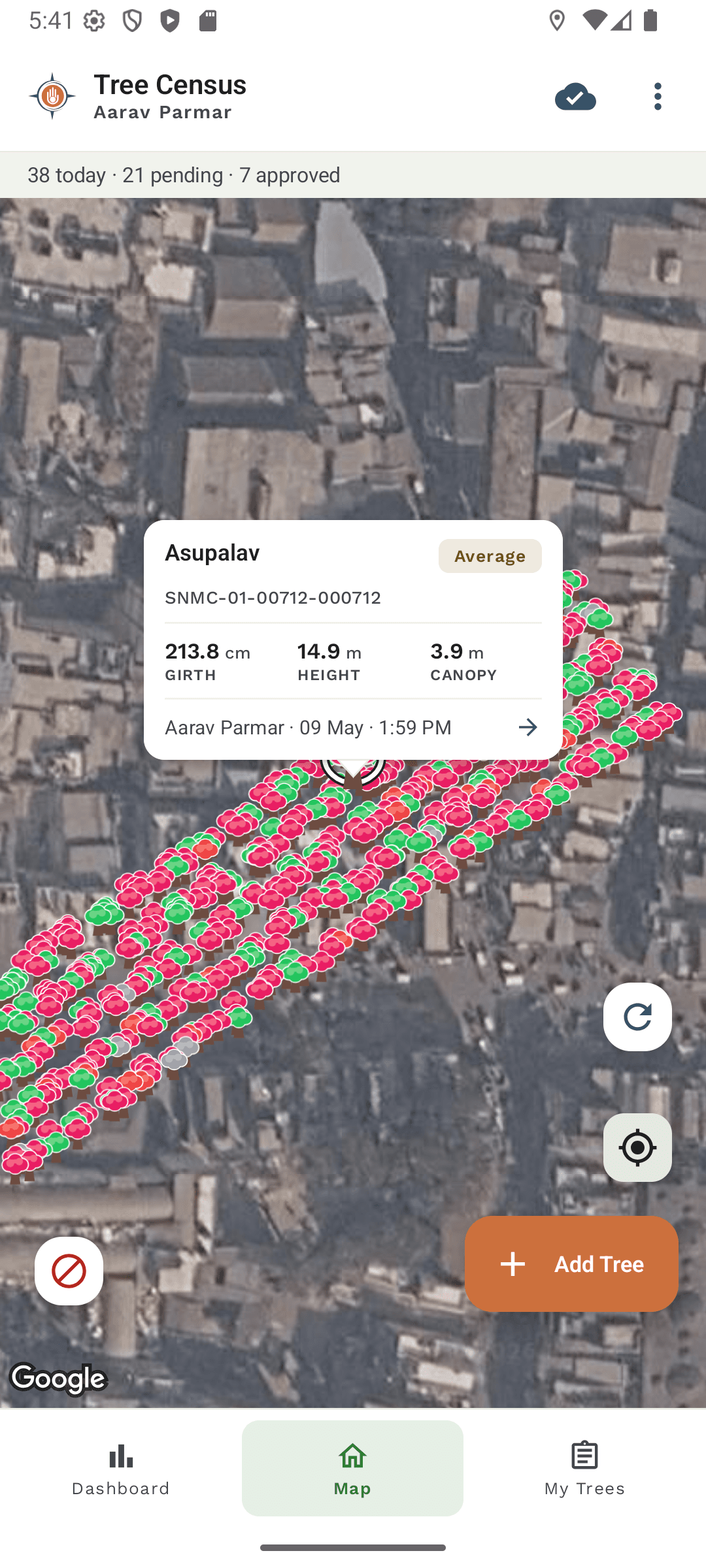
A field-first Android client
Field conditions are the hardest part of this product. Surveyors are outdoors, often on flaky connectivity, capturing photos with GPS coordinates, and supervisors need to review thousands of trees on a map without a 600 ms map re-init every time they switch tabs.
The single decision that shaped the Android architecture was treating the map as a long-lived shell rather than a screen: the Compose MapShell keeps Google Maps composed for the full lifetime of the home experience and only swaps overlay z-index when the user moves between map, dashboard, and add-tree flows. The viewport is the unit of map work end-to-end — the backend exposes a bounding-box endpoint and a cheap change-detection check, and the client never tries to mirror the entire city's markers locally. Room is reserved for the surveyor's own offline drafts and sync state, not as a remote map cache.
Decisions I am proud of
This project forced decisions across the whole stack. A change to map-marker pagination ripples through backend query shape, Android state, web dashboard assumptions, and field usability. An auth change is not just a login page; it touches mobile credential flows, backend token verification, dashboard cookies, production env, and runbooks.
The work I am most proud of sits in that connective tissue: reducing map and sync load without sacrificing field correctness; locking the platform down to a single Google Sign-In contract across web and mobile; turning deployment notes into a repeatable VM and GCP runbook plus a manual-only deploy workflow that uses Workload Identity Federation instead of long-lived service-account keys; treating screenshots, exports, logs, and monitoring as part of the product, not afterthoughts; and keeping local debug, production, Android release, and cloud operations clearly separated so an emergency reset cannot leak into a routine deploy.
What I would harden next
The current production posture is enough to run the first city responsibly, but there is a clear next slice: replace runtime GCS access keys with a tighter VM service-account posture using Workload Identity for runtime, not just CI; move Cloud SQL connectivity to the Cloud SQL Auth Proxy or a private path instead of public-IP allowlisting; wire alert policies to a real notification channel once traffic patterns settle and false-positive rates are characterized; add runtime panels around photo upload retries, sync failures, and mobile API latency so field issues surface before the help-desk does; and expand device-level test passes for camera capture, GPS accuracy, and offline recovery on a wider device matrix.
Tree Census is the kind of project I like building: real users, messy field constraints, geospatial data, mobile performance tradeoffs, cloud operations, and enough surface area that architecture decisions have to survive contact with production.